Unidade de transferência
Em sistemas de computação, a eficiência e a rapidez com que os dados são transferidos entre a CPU e a memória são cruciais para o desempenho geral do sistema. Duas importantes unidades de transferência são a palavra e o bloco, cada uma com suas características e funções específicas.
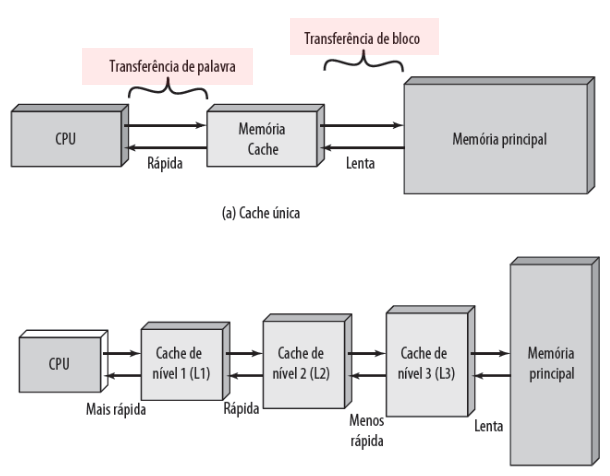
Transferência de palavra
Uma palavra é a unidade básica de dados que a CPU pode processar de uma vez. O tamanho de uma palavra varia conforme a arquitetura do sistema e pode ser de 8, 16, 32, 64 bits ou mais.
Importância
-
Processamento: A palavra é a quantidade de dados que a CPU pode manipular em uma única operação. Por exemplo, em uma arquitetura de 32 bits, a CPU pode processar 32 bits de dados simultaneamente.
-
Endereçamento: Cada palavra na memória tem um endereço único, permitindo que a CPU acesse dados específicos de maneira eficiente.
Aplicação
A CPU lê e escreve palavras na memória principal durante a execução de instruções. Operações aritméticas e lógicas são realizadas sobre palavras.
Transferência de bloco
Um bloco é um conjunto de várias palavras que são transferidas entre a memória principal e a cache ou entre a memória principal e os dispositivos de armazenamento secundário.
Importância
-
Eficiência: Transferir dados em blocos, em vez de palavras individuais, aumenta a eficiência, pois reduz o número de operações de leitura/escrita necessárias.
-
Cache: A memória cache armazena dados em blocos. Quando a CPU precisa de dados, é mais eficiente carregar um bloco inteiro na cache, pois é provável que os dados adjacentes também sejam usados em breve.
Aplicação
Blocos são usados em transferências de dados entre diferentes níveis da hierarquia de memória (por exemplo, entre a RAM e a cache, ou entre a RAM e um disco rígido).
Exemplo
Considere a situação que você desenvolveu um algoritmo capaz de somar os elementos de um vetor.
import java.util.Random;
public class Main {
public static void main(String[] args) {
Random rnd = new Random();
int[] vetor = new int[10];
for (int i = 0; i < vetor.length; i++)
vetor[i] = rnd.nextInt(100);
int soma = 0;
for (int i = 0; i < 10; i++)
soma += vetor[i];
System.out.println("Soma = " + soma);
}
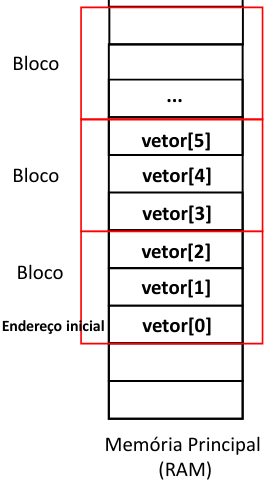
}Suponha que o vetor em questão tenha os seguintes elementos.

A representação desse vetor na memória é:
Nota
Lembrando que um vetor é uma estrutura de dados estático que ocupa um espaço contíguo na memória.
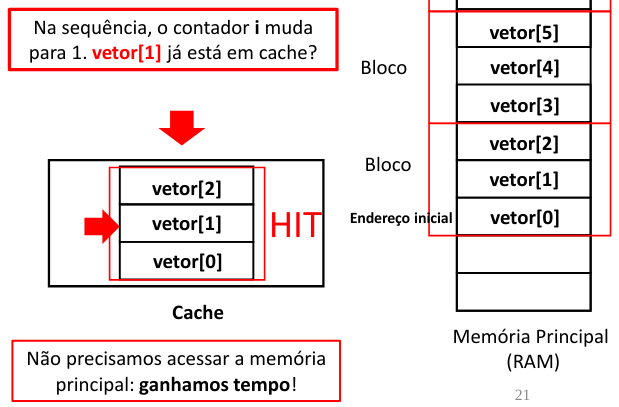
Agora, vamos analisar passo a passo a execução do algoritmo em questão para entendermos melhor o acesso a memória cache e principal.
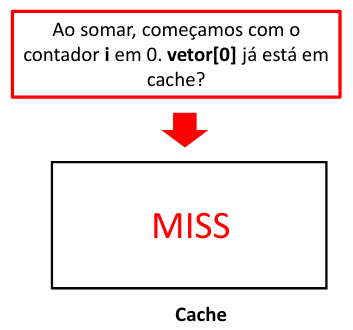
Nota
Ao buscar o dados no cache, depara-se com um “miss” o qual gera o acesso à memória principal e, consequentemente, mais tempo para acessar os dados.
Dessa forma os dados buscados em bloco na memória principal são carregados para a memória cache.
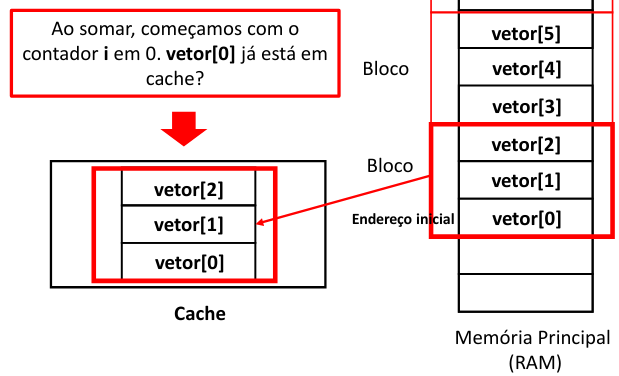
Na próxima iteração, o dados da posição 1 do vetor já foi carregado na memória, pois como os dados são carregados em blocos para o cache, isso causa um ganho de desempenho ao gerar um “Hit” ao acessar o dado na memória cache.