O algoritmo DBSCAN, que significa “Density-based spatial clustering of applications with noise” (Agrupamento espacial baseado em densidade de aplicações com ruído), é uma técnica de agrupamento que se concentra em encontrar grupos de pontos de dados com base na densidade espacial. Diferentemente do K-Means, o DBSCAN não exige que você especifique o número de clusters antecipadamente, o que é uma vantagem significativa. Além disso, geralmente, apresenta resultados melhores e é mais rápido que o K-Means em muitos cenários.
Funcionamento
-
Escolha de pontos aleatórios e traçado de raio: O algoritmo começa selecionando um ponto de dados aleatório no conjunto de dados. A partir desse ponto, ele traça um raio com um limite de distância chamado “threshold distance” (distância limite). Todos os pontos de dados que estão dentro desse raio são considerados parte do mesmo grupo.
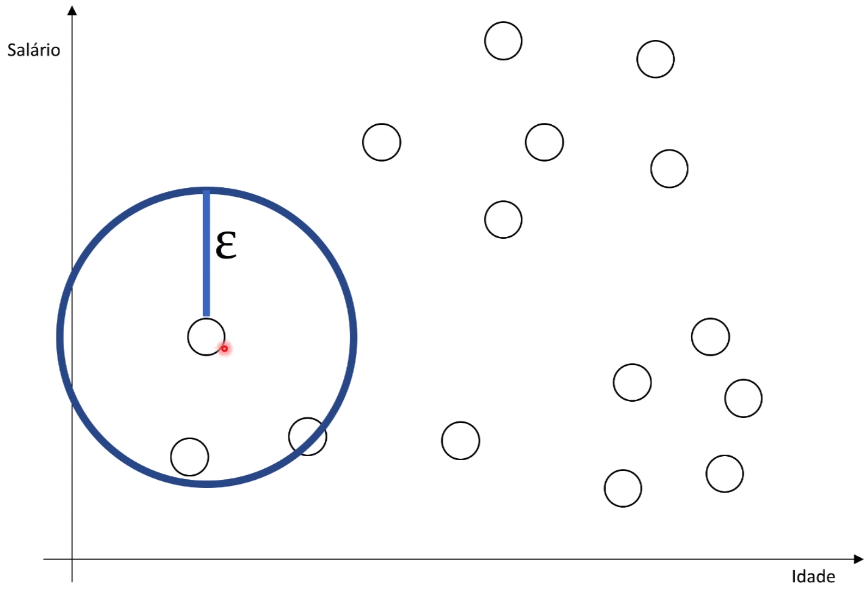
-
Expansão para pontos próximos: O algoritmo então verifica os pontos que estão dentro do raio traçado. Se houver pontos suficientes (mais do que um valor mínimo especificado), o algoritmo expande o grupo para incluir esses pontos. Isso é feito iterativamente até que não haja mais pontos para adicionar ao grupo.
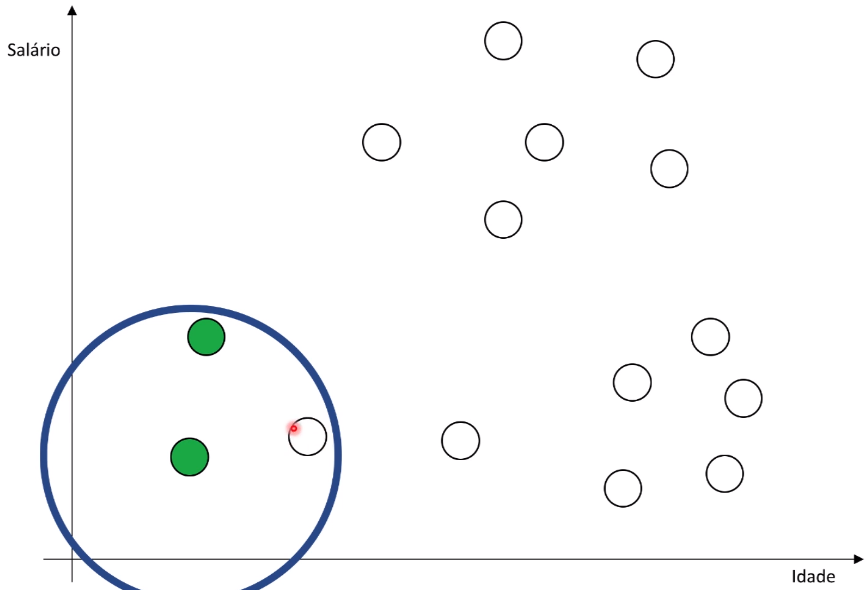
-
Repetição para outros pontos: O processo é repetido para outros pontos que não foram atribuídos a nenhum grupo até que todos os pontos tenham sido considerados.
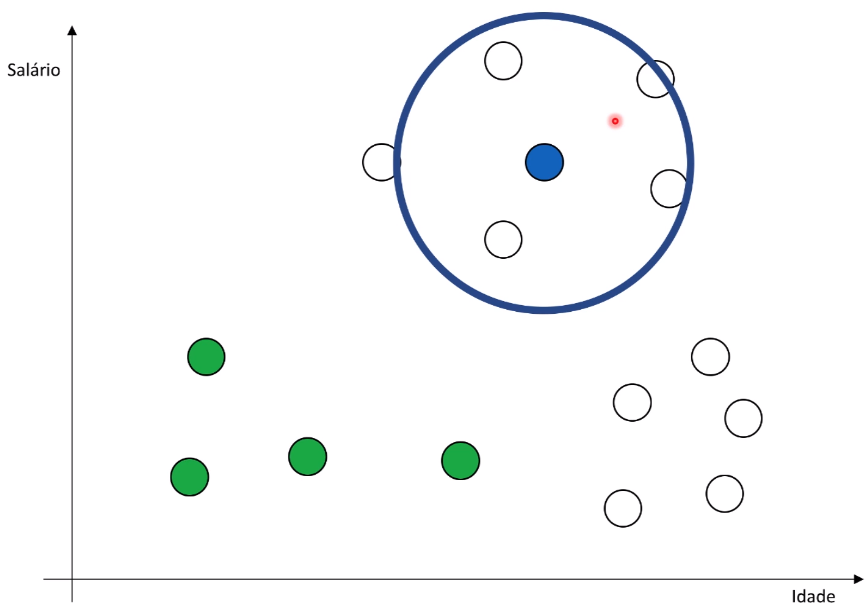
-
Agrupamento final: Após a conclusão do algoritmo, os pontos de dados são atribuídos a grupos com base em sua proximidade uns com os outros. Os pontos que não se encaixam em nenhum grupo são rotulados como outliers ou ruído.
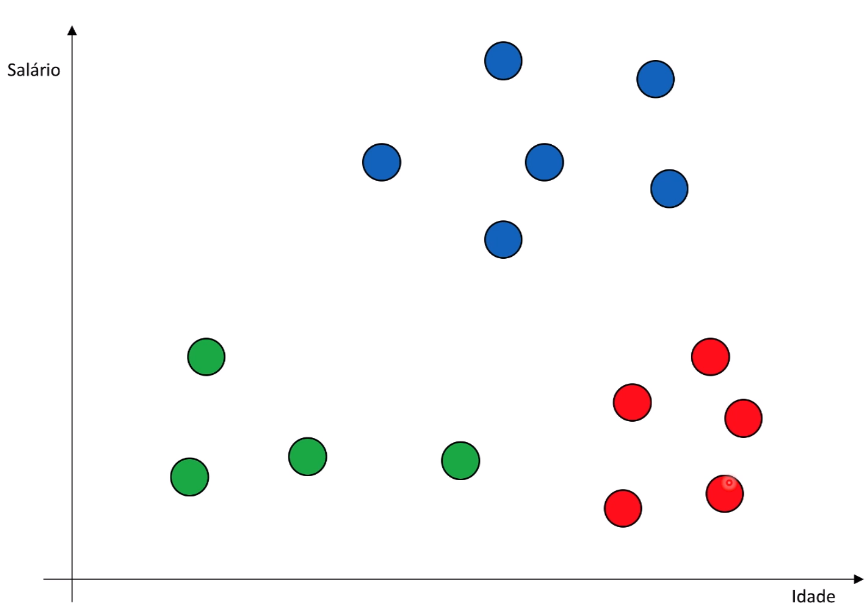
Vantagens
-
Encontra padrões não lineares: O DBSCAN é eficaz na identificação de clusters com formas não lineares, o que o torna superior ao K-Means em muitos casos.
-
Robusto contra outliers: O algoritmo é resistente a pontos de dados que não pertencem a nenhum cluster. Esses pontos são geralmente rotulados como ruído.
-
Independente da inicialização: Diferentemente do K-Means, onde a inicialização dos centróides pode afetar o resultado, o DBSCAN não é sensível à inicialização.
Desvantagens
-
Sensibilidade à escolha do parâmetro de distância limite: Encontrar o valor ideal para o parâmetro de distância limite (threshold distance) pode ser um desafio e pode afetar significativamente o resultado do agrupamento.
-
Sensível à ordem dos dados: A ordem em que os pontos de dados são processados pelo algoritmo pode afetar o resultado do agrupamento. Em outras palavras, um ponto pode pertencer a diferentes clusters dependendo da ordem em que os dados são apresentados.
Em resumo, o DBSCAN é um algoritmo de agrupamento que se baseia na densidade espacial, permitindo a detecção de grupos de pontos de dados sem a necessidade de especificar antecipadamente o número de clusters. Ele é eficaz em encontrar padrões não lineares, é robusto contra outliers e não é sensível à inicialização. No entanto, encontrar o valor ideal para o parâmetro de distância limite pode ser um desafio.