O algoritmo K-Means, também conhecido como o algoritmo de Lloyd, é uma das técnicas de agrupamento mais populares e amplamente utilizadas na área de mineração de dados e aprendizado de máquina. Ele é usado para agrupar dados não rotulados em clusters ou grupos com base em suas características similares.
O processo de agrupamento no algoritmo de K-Means (Lloyd) é executado nas seguintes etapas:
-
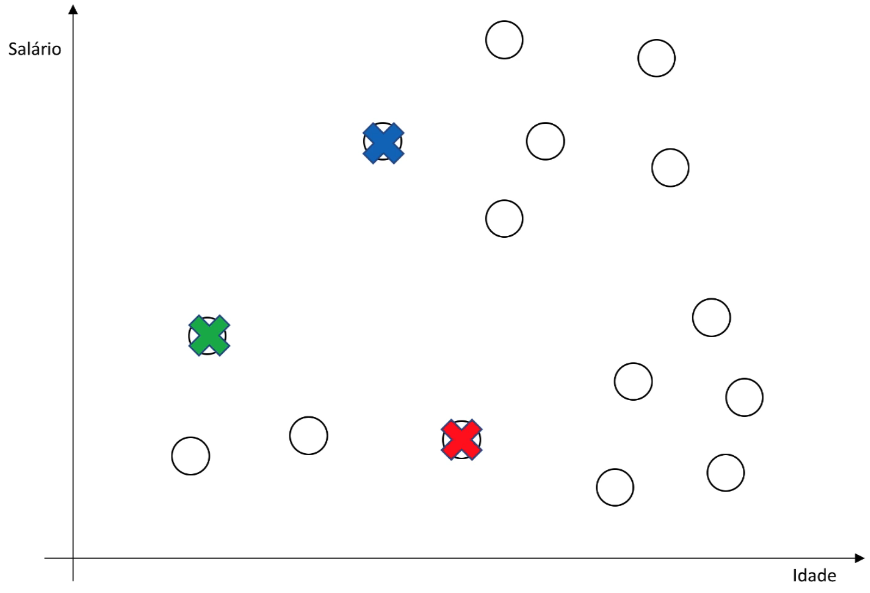
Inicialização dos centroides
A primeira etapa envolve a inicialização dos centroides, que são os pontos que representam o centro de cada cluster. Inicialmente, um número fixo de K centroides (geralmente definido pelo usuário) é colocado aleatoriamente no espaço de dados. Cada centroide é uma representação inicial de um grupo de pontos.
-
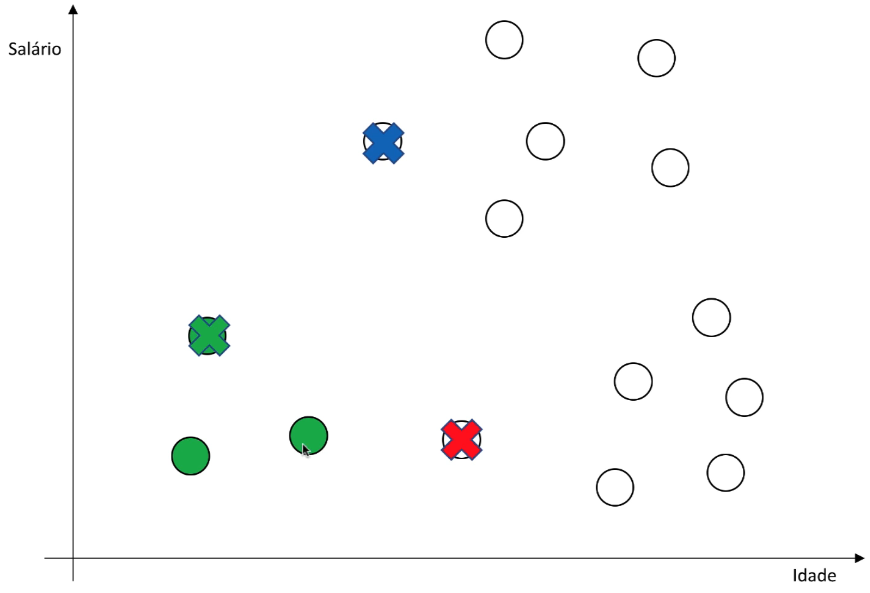
Atribuição aos Clusters
Para cada ponto na base de dados, é calculada a distância entre esse ponto e todos os centroides. O ponto é então associado ao cluster representado pelo centroide mais próximo. Essa etapa é fundamental para determinar a qual grupo cada ponto pertence.
-
Atualização dos Centroides
Após a atribuição inicial, os centroides são recalculados. Isso é feito calculando a média de todos os pontos que foram associados a cada centroide durante a etapa de atribuição. O novo centroide é então movido para a posição média desses pontos.

-
Iteração
Os passos 2 e 3 são repetidos iterativamente até que os centroides não se movam significativamente entre as iterações ou um critério de parada predefinido seja atingido. O critério de parada pode ser baseado no número máximo de iterações, na convergência dos centroides ou em outros fatores específicos do problema.
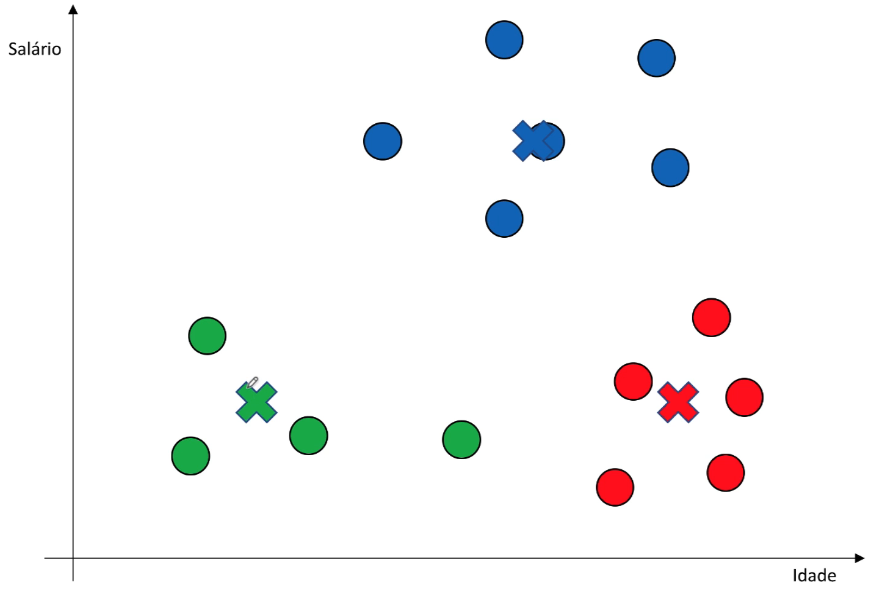
O algoritmo de K-Means converge quando os centroides não se movem significativamente e, nesse ponto, os grupos finais estão formados. Os objetos pertencentes ao mesmo cluster têm características similares entre si, enquanto objetos de clusters diferentes têm características distintas.