Introdução ao algoritmo SVM
O SVM (Support Vector Machine) é um algoritmo de aprendizado de máquina que é amplamente utilizado para tarefas de classificação e regressão. Ele é particularmente eficaz quando se trata de problemas de separação de classes complexas e não lineares. O SVM baseia-se na ideia de encontrar um hiperplano que melhor separe as classes no espaço de características.
A ideia central por trás do SVM é encontrar um hiperplano com margem máxima entre as classes. A margem é a distância entre o hiperplano e os exemplos de treinamento mais próximos de cada classe, conhecidos como vetores de suporte. Esses vetores de suporte são os exemplos mais difíceis de classificar e são cruciais para determinar a posição e orientação do hiperplano de decisão.
Em um cenário bidimensional, imagine um conjunto de pontos de duas classes diferentes em um gráfico. O SVM tenta encontrar uma linha reta (há casos em que pode ser uma superfície hiperplana em espaços de dimensão superior) que divida esses pontos da melhor maneira possível, maximizando a distância entre a linha e os pontos mais próximos de cada classe. Veja a imagem a baixo:
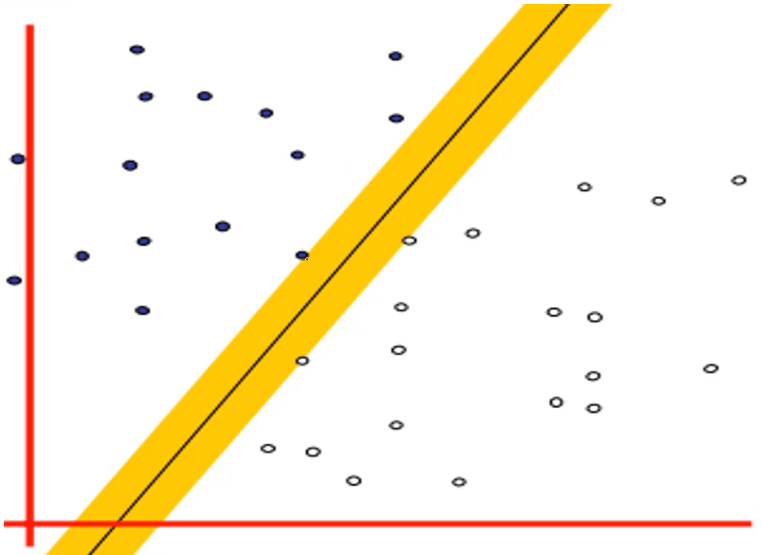
O SVM pode ser usado para dois tipos principais de problemas:
-
Classificação: Nesse caso, o SVM tenta encontrar um hiperplano que separe as classes. Dependendo da natureza dos dados e da separação, esse hiperplano pode ser linear ou não linear (usando truques de kernel).
-
Regressão: O SVM também pode ser usado para problemas de regressão, onde o objetivo é encontrar uma função que melhor se ajuste aos dados, tentando manter a margem ao redor da curva de ajuste.
Além disso, o SVM usa a técnica conhecida como “kernel trick” para mapear os dados originais em um espaço de dimensão superior, permitindo que ele lide com problemas que não podem ser separados linearmente no espaço original.
Vantagens
-
Eficaz em base de dados de alta dimensão.
-
Pode lidar com dados não lineares usando kernels.
-
Eficiente em uso de memória devido à seleção de vetores de suporte.
-
Aprende conceitos não presentes nos dados originais
-
Mais fácil de utilizar comparado com redes neurais
Limitações
-
Pode ser sensível à escolha de parâmetros e configurações.
-
Pode ser computacionalmente caro para grandes conjuntos de dados.
-
Pode ser desafiador escolher o kernel adequado.
-
Não é possível ter uma visualização do modelo resultante (denotado black box ou caixa preta)
Conclusão
Em resumo, o SVM é um algoritmo versátil e poderoso que é usado para classificação e regressão. Ele encontra um hiperplano (ou curva) que melhor separa ou se ajusta aos dados, buscando maximizar a margem entre as classes.
É uma ferramenta valiosa para problemas complexos de aprendizado de máquina, especialmente quando os dados são desafiadores de serem separados linearmente.