A classe AgglomerativeClustering no módulo sklearn.cluster implementa o algoritmo de agrupamento aglomerativo, que é uma técnica de agrupamento hierárquico. Esse algoritmo é usado para agrupar amostras em clusters hierárquicos, criando uma árvore de clusters (dendrograma). Essa árvore pode ser visualizada posteriormente para entender as relações hierárquicas entre os clusters.
Sintaxe
from sklearn.cluster import AgglomerativeClustering
cluster = AgglomerativeClustering()Principais parâmetros
-
n_clusters (int, opcional, padrão=2): O número de clusters que o algoritmo deve formar. Se não for especificado, o algoritmo formará dois clusters por padrão.
-
affinity (string ou callable, opcional, padrão=“euclidean”): A métrica de distância a ser usada para calcular a similaridade entre as amostras. Pode ser uma das métricas de distância predefinidas do
scikit-learn, como “euclidean” (distância euclidiana), “manhattan” (distância de Manhattan), “cosine” (similaridade cosseno), entre outras. Você também pode fornecer uma função personalizada para calcular a similaridade. -
linkage (string, opcional, padrão=“ward”): O critério de ligação (linkage criterion) a ser usado para determinar a distância entre os clusters. Os valores possíveis incluem “ward” (minimização da variância dos clusters), “complete” (distância máxima), “average” (média das distâncias), “single” (distância mínima), entre outros.
-
compute_full_tree (bool, opcional, padrão=True): Se definido como True, o algoritmo construirá a árvore de clusters completa. Se definido como False, ele usará uma estratégia de redução de custos para calcular a árvore de clusters parcial.
-
distance_threshold (float, opcional, padrão=None): Se definido, o algoritmo interromperá a criação de clusters quando a distância entre os clusters exceder esse limite.
Principais métodos
-
fit(X): Este método ajusta o modelo aos dados de entrada
X. Ele calcula os clusters com base nos parâmetros especificados e nos dados de entrada. -
fit_predict(X): Este método ajusta o modelo aos dados de entrada
Xe retorna os rótulos dos clusters a que cada amostra pertence.
Principais atributos
- labels_: Este atributo armazena os rótulos dos clusters atribuídos a cada amostra após a chamada ao método
fit_predict.
Exemplo
from sklearn.cluster import AgglomerativeClustering
import numpy as np
# Base de dados
x = [20, 27, 21, 37, 46, 53, 55, 47, 52, 32, 39, 41, 39, 48, 48]
y = [1000, 1200, 2900, 1850, 900, 950, 2000, 2100, 3000, 5900, 4100, 5100, 7000, 5000, 6500]
base_salary = np.array([
[age, salary]
for age, salary in zip(x, y)
])
# Criar uma instância do modelo
hc_salary = AgglomerativeClustering(n_clusters=3, linkage="ward", affinity="euclidean")
# Ajustar o modelo aos dados
labels = hc_salary.fit_predict(base_salary)
# Exibição dos rótulos dos clusters
graph = px.scatter(x = base_salary[:,0], y = base_salary[:,1], color = labels)
graph.show()Saída:
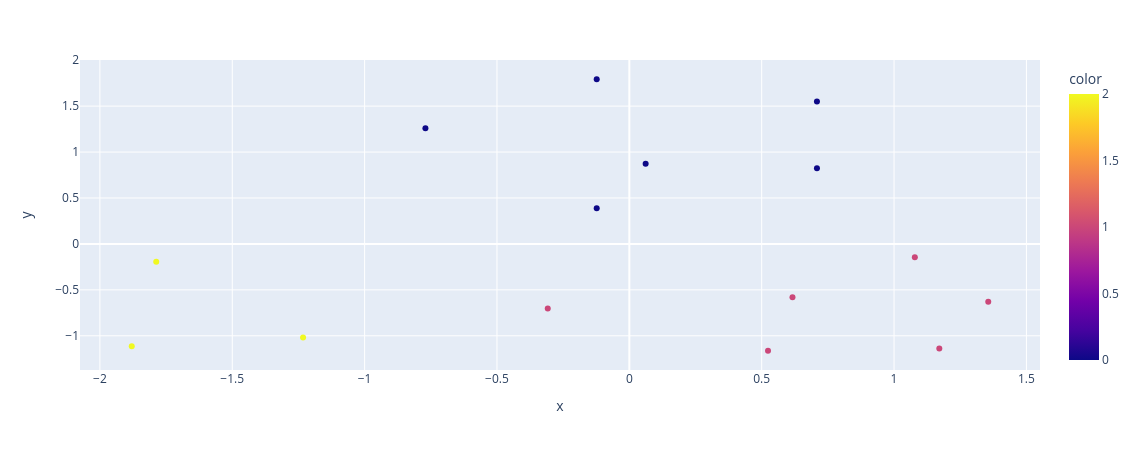
Neste exemplo, geramos dados aleatórios, criamos uma instância do modelo AgglomerativeClustering com 3 clusters e ajustamos o modelo aos dados. O método fit_predict retorna os rótulos dos clusters atribuídos a cada amostra.