A subamostragem (under sampling) e a sobreamostragem (oversampling) são técnicas de pré-processamento de dados usadas para lidar com conjuntos de dados desequilibrados, nos quais uma classe é representada por muito menos exemplos do que outra classe. Essa desigualdade na distribuição das classes pode levar a problemas de desempenho nos modelos de aprendizado de máquina, pois os modelos podem ficar enviesados em direção à classe majoritária, resultando em classificações incorretas da classe minoritária.
Subamostragem (Under sampling)
A subamostragem envolve a redução do número de exemplos da classe majoritária para igualar o número de exemplos da classe minoritária. Isso é feito removendo aleatoriamente exemplos da classe majoritária até que o equilíbrio seja alcançado. A ideia por trás da subamostragem é reduzir a influência da classe majoritária, tornando o conjunto de dados mais equilibrado.
Vantagens da subamostragem
- Reduz o risco de superajuste (over fitting) nos modelos.
- Pode melhorar o desempenho em conjuntos de dados muito desequilibrados.
Desvantagens da subamostragem
- Pode resultar na perda de informações valiosas ao descartar exemplos da classe majoritária.
- Pode não ser eficaz em conjuntos de dados em que a classe minoritária é muito pequena.
Sobreamostragem (Oversampling)
A sobreamostragem envolve a geração de exemplos adicionais da classe minoritária para igualar o número de exemplos da classe majoritária. Isso é feito replicando ou sintetizando dados da classe minoritária. A ideia por trás da sobreamostragem é aumentar a representação da classe minoritária, tornando o conjunto de dados mais equilibrado.
Vantagens da sobreamostragem
- Aumenta a representação da classe minoritária, tornando os modelos mais robustos.
- Pode ser mais eficaz em conjuntos de dados em que a classe minoritária é muito pequena.
Desvantagens da sobreamostragem
- Pode aumentar o risco de superajuste (over fitting) nos modelos, especialmente se a geração de dados sintéticos não for cuidadosamente controlada.
- Pode introduzir viés nos modelos se a geração de dados sintéticos não for realizada de forma apropriada.
Técnicas Comuns de Subamostragem e Sobreamostragem
Existem várias técnicas comuns para subamostragem e sobreamostragem, incluindo:
-
Tomek Links: Identifica e remove pares de exemplos (um da classe majoritária e outro da classe minoritária) que são “ligados”, ou seja, têm uma distância pequena entre si.
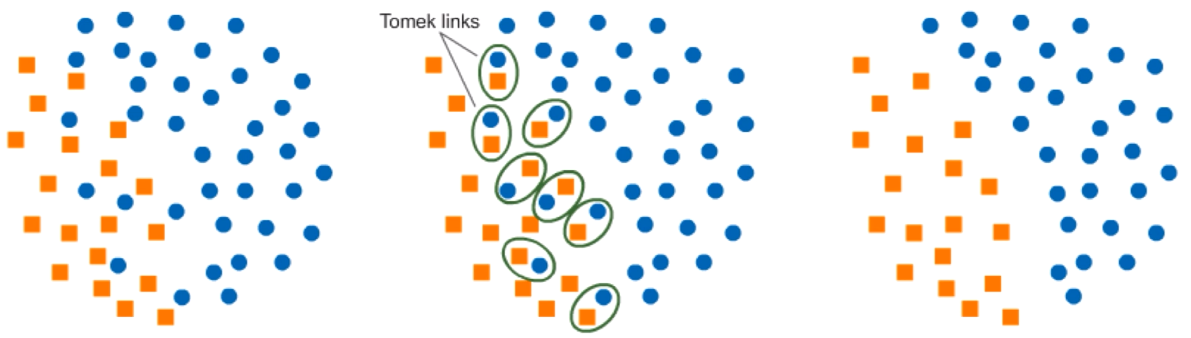
-
SMOTE (Synthetic Minority Over-sampling Technique): Gera exemplos sintéticos da classe minoritária interpolando características de exemplos existentes com base no cálculo da distância.
-
Subamostragem Aleatória: Aleatoriamente remove exemplos da classe majoritária até que o equilíbrio seja alcançado.
-
Sobreamostragem Aleatória: Aleatoriamente replica exemplos da classe minoritária até que o equilíbrio seja alcançado.
-
ADASYN (Adaptive Synthetic Sampling): Gera exemplos sintéticos da classe minoritária com base na densidade local de exemplos.
A escolha entre subamostragem e sobreamostragem depende do conjunto de dados específico e do problema em questão. Em alguns casos, pode ser útil experimentar ambas as abordagens e avaliar qual delas funciona melhor para o seu modelo. Além disso, é importante ter em mente que o pré-processamento de dados desequilibrados é uma etapa crítica na construção de modelos precisos em tais cenários.