Função “plot_tree”
A função plot_tree do módulo sklearn.tree é utilizada para visualizar a estrutura de uma árvore de decisão criada com o algoritmo DecisionTreeClassifier ou DecisionTreeRegressor do scikit-learn. Essa função permite que os usuários observem graficamente como a árvore foi construída e como os dados são divididos em cada nó da árvore.
Sintaxe
from sklearn.tree import plot_tree
plot_tree(decision_tree, feature_names=None, class_names=None, filled=True, rounded=True, impurity=True)Parâmetros:
-
decision_tree: O modelo de árvore de decisão criado pelo DecisionTreeClassifier ou DecisionTreeRegressor que se deseja visualizar. -
feature_names(opcional): Uma lista contendo os nomes das características (atributos) usados na árvore. Se não for fornecido, serão usados nomes genéricos como “feature_0”, “feature_1”, etc. -
class_names(opcional): Uma lista contendo os nomes das classes de saída do modelo, usadas em problemas de classificação. Se não for fornecido, serão usados valores numéricos para representar as classes. -
filled(opcional): Um valor booleano que indica se os nós da árvore serão coloridos para mostrar a classe de destino mais frequente para problemas de classificação ou a média dos valores de destino para problemas de regressão. -
rounded(opcional): Um valor booleano que indica se os nós da árvore terão bordas arredondadas. -
impurity(opcional): Um valor booleano que indica se a impureza dos nós será mostrada. A impureza é uma medida de quão misturados estão os dados em cada nó da árvore.
Exemplo
from sklearn.tree import DecisionTreeClassifier
from sklearn.tree import plot_tree
import matplotlib.pyplot as plt
# Carregar o conjunto de dados de crédito
with open("credit.pkl", "rb") as file:
X_credit_train, y_credit_train, X_credit_test, y_credit_test = pickle.load(file)
# Criar o modelo de árvore de decisão
credit_tree = DecisionTreeClassifier(criterion="entropy", random_state=0)
credit_tree.fit(X_credit_train, y_credit_train)
# Visualizar a árvore de decisão
forecasters = ["income", "age", "loan"]
fig, axis = plt.subplots(nrows=1, ncols=1, figsize=(20, 20))
credit_class_names = [str(i) for i in credit_tree.classes_]
tree.plot_tree(credit_tree, feature_names=forecasters, class_names=credit_class_names, filled=True)Saída:
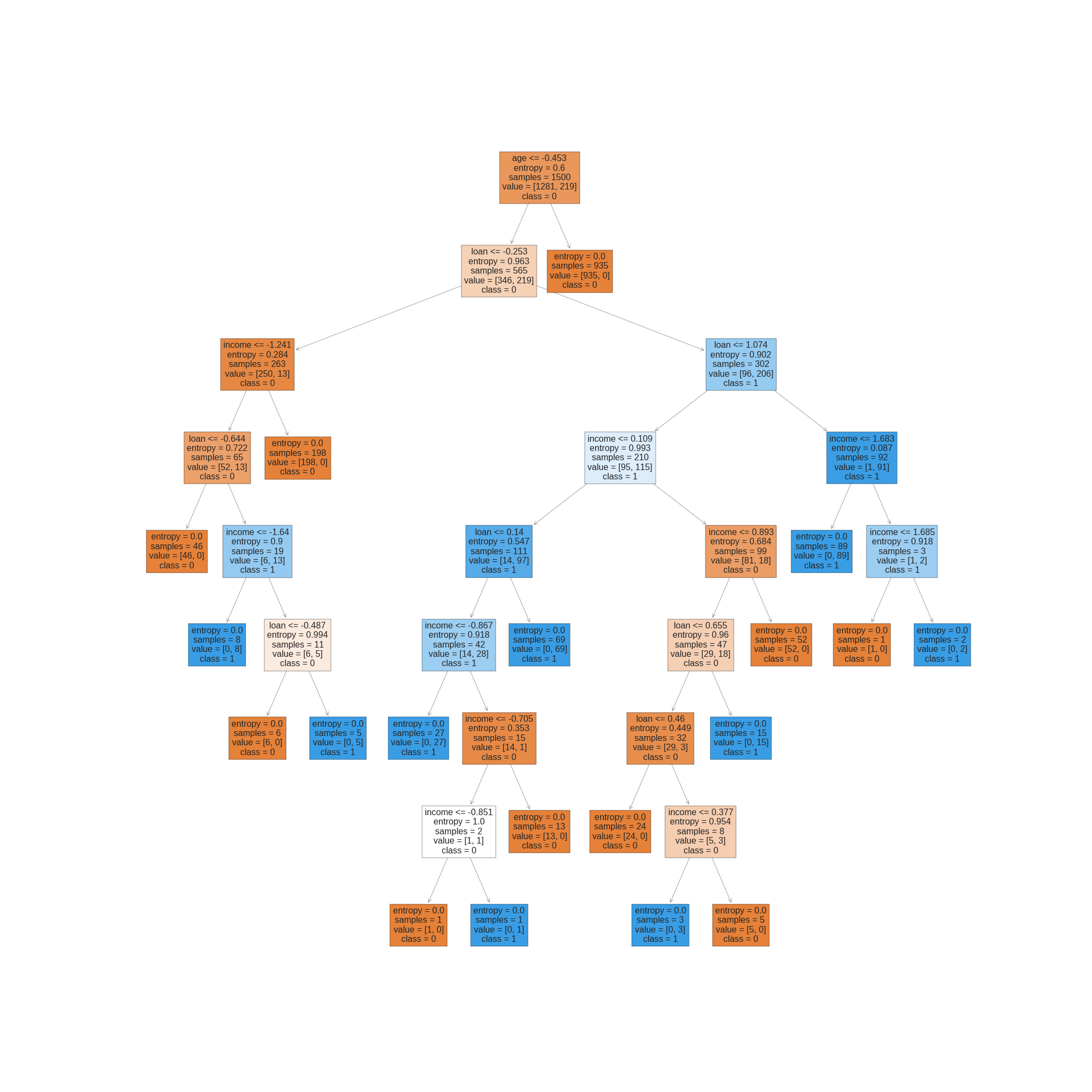
No exemplo acima, carregamos o conjunto de dados de crédito, criamos um modelo de árvore de decisão e o ajustamos aos dados. Em seguida, utilizamos a função plot_tree para visualizar a árvore criada. O parâmetro feature_names é usado para fornecer os nomes das características do conjunto de dados, o parâmetro class_names é usado para fornecer os nomes das classes de saída e os parâmetros filled, rounded e impurity são usados para estilizar a visualização da árvore.
Conclusão
A visualização da árvore de decisão mostra como os dados são divididos em cada nó, quais as características são usadas para fazer as divisões e a classe de destino associada a cada nó terminal. Essa visualização é uma ferramenta útil para entender como a árvore toma decisões com base nos dados de entrada.