Introdução ao Kafka Connect
Definição
É um componente gratuito e open-source do Apache Kafka.
Ele exerce uma função parecida com um hub de dados centralizado para integrações simples entre sistemas de armazenamento de dados (banco de dados, key-value store, search indexes e file systems).
IMPORTANTE: o Kafka Connect NÃO é uma ferramenta de ETL (Extract, Transform, Load), mas é possível realizar transformações simples a partir de um recurso chamado SMT (Simple Message Transformation)
Dinâmica de funcionamento
Estrutura
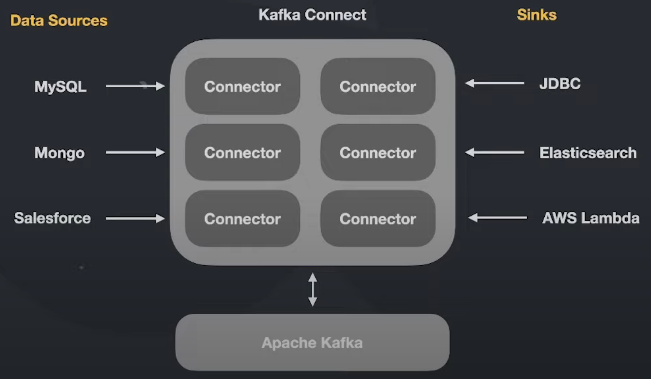
Existem 2 clusters (Apache Kafka e Kafka Connect) que se comunicam entre si.
O Kafka Connect possui vários conectores (connectors). Existem 2 tipos de conectores:
-
Data Source Connectors: conectam com fontes de dados (MySQL) e inserem esses dados (contidos no MySQL) dentro de uma fila no Apache Kafka
-
Sinks: entregam os dados a um serviço (JDBC, Elasticsearch, AWS Lambda)
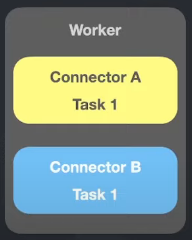
Standalone Workers
É um worker que é responsável por executar uma tarefa.
worker: geralmente é uma máquina
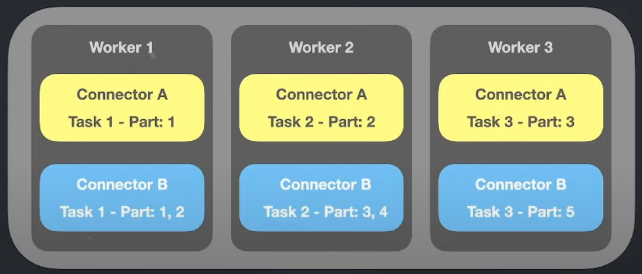
Distributed Workers
É um cluster que possui vários workers, logo as tarefas são distribuídas entre os conectores de cada worker.
Configuração de um conector
Propriedades
-
name: nome do conector -
connector.class: classe do conector (clonar o repositório ou instalar via Confluent Hub CLI) -
kafka.status.topic: tópico responsável por armazenas os dados extraídos de uma fonte de dados (utilizado em Data Source Connectors)
Exemplo
name = twitter
connector.class = com.github.jcustenborder.kafka.connect.twitter.TwitterSourceConnector
twitter.oauth.consumerKey = XXXXXXXXXXXXXXXXXXXXXXXXXXXX
twitter.oauth.consumerSecret = XXXXXXXXXXXXXXXXXXXXXXXXXXXX
twitter.oauth.accessToken = XXXXXXXXXXXXXXXXXXXXXXXXXXXX
twitter.oauth.accessTokenSecret = XXXXXXXXXXXXXXXXXXXXXXXXXXXX
filter.keywords = bbb
kafka.status.topic = tweets
process.deletes = false